
OCR・テキスト整備
OCR結果や入力データ、ファイル名、項目名を整え、誤読や表記ゆれを減らします。正確なテキストが、その後の検索・分類の土台になります。
STRUCTURING / AI
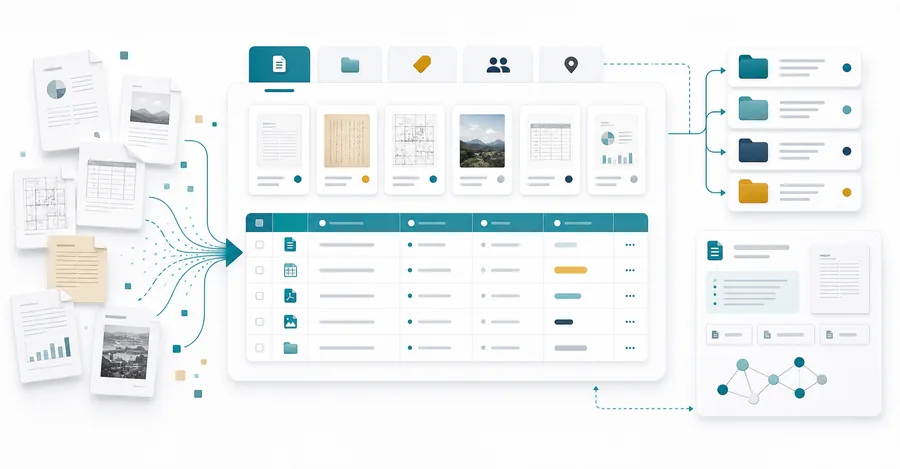
紙資料をスキャンしテキスト化しても、その多くは画像やテキストの集まりにすぎません。ファイル名が不統一、OCRの誤読、属性が不明確。こうした状態では検索も分析も効率が落ちます。誠勝は、既に電子化した資料を「探せる・分類できる・AIや社内システムとつながる」構造化データへ整えます。

WHAT WE ORGANIZE
検索や分析の精度は、元データの整い方で決まります。資料の状態と活用目的に合わせて、次の3つを整えます。
OCR結果や入力データ、ファイル名、項目名を整え、誤読や表記ゆれを減らします。正確なテキストが、その後の検索・分類の土台になります。

資料名、年代、分類、部門、権利、公開範囲などの属性を設計します。属性が揃うと、いつの資料か、どの部門の資料か、どんな資料かで必要なものを絞り込めるようになります。

社内検索や問い合わせ対応で使えるよう、AIが扱いやすい単位にデータを分け、整えます。質問に対して関連する資料を返せる状態を目指します。
POSITION
電子化したデータをそのまま保管しているだけでは、全件検索や確認作業が人手に頼りがちです。構造化は、デジタルアーカイブ、内部統制、AI活用に進むための前提になります。
資料の種類、既存データの状態、検索やAI活用の目的を確認します。
誤読、表記ゆれ、ファイル名、項目名を整理し、検索しやすいテキストへ整えます。
資料名、年代、分類、権利、公開範囲など、管理と活用に必要な属性を設計します。
AIが扱いやすい単位にデータを分け、社内検索やRAGへ接続しやすい形にします。
すでに電子化されたデータの正確さ、属性、AI活用への準備を整えます。
仕分け、スキャン実務、統合企画、機材選定は、それぞれの専門ページでご相談ください。
社内文書をスキャンしたが検索が進まない、入力前に品質を整えたい、生成AIやRAGで資料を活用したい、複数部門の資料を一元管理したい場合に向いています。
OCR精度が低い場合、DublinCoreなどのメタデータ標準と現場項目の両立、既存DBやシステム連携、期間の目安などは、サンプル確認の上で提案します。
電子化済みの資料を活かすための構造化について、資料形態、規模、利用目的をお伺いした上で最適な進め方をご提案します。